9 Lệnh Kiểm Tra Dung Lượng Ổ Cứng HDD Trên Linux
Trong bài viết này mình sẽ giới thiệu tới các bạn các câu lệnh kiểm tra dung lượng ổ cứng hdd cho các bạn mới và các bạn đã sử dụng linux lâu năm.
fdisk
Đây là câu lệnh có thể hiển thị chi tiết các partitions trên một ổ đĩa, câu lệnh thường được sử dụng để kiểm tra các partition, nhưng nhượt điểm của câu lệnh này không hiển thị dung lượng của từng partition. Sau đây là ví dụ về cậu lệnh fdisk
$ sudo fdisk -l Disk /dev/sda: 500.1 GB, 500107862016 bytes 255 heads, 63 sectors/track, 60801 cylinders, total 976773168 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x30093008 Device Boot Start End Blocks Id System /dev/sda1 * 63 146801969 73400953+ 7 HPFS/NTFS/exFAT /dev/sda2 146802031 976771071 414984520+ f W95 Ext'd (LBA) /dev/sda5 146802033 351614654 102406311 7 HPFS/NTFS/exFAT /dev/sda6 351614718 556427339 102406311 83 Linux /dev/sda7 556429312 560427007 1998848 82 Linux swap / Solaris /dev/sda8 560429056 976771071 208171008 83 Linux Disk /dev/sdb: 4048 MB, 4048551936 bytes 54 heads, 9 sectors/track, 16270 cylinders, total 7907328 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0x0001135d Device Boot Start End Blocks Id System /dev/sdb1 * 2048 7907327 3952640 b W95 FAT32
sfdisk
Câu lệnh sfdisk cũng tương tự như fdisk nhưng nó có nhiều tính năng hơn, nó có khả năng thể hiện dung lượng của từng partition và tính bằng đơn vị Mb
$ sudo sfdisk -l -uM
Disk /dev/sda: 60801 cylinders, 255 heads, 63 sectors/track
Warning: extended partition does not start at a cylinder boundary.
DOS and Linux will interpret the contents differently.
Units = mebibytes of 1048576 bytes, blocks of 1024 bytes, counting from 0
Device Boot Start End MiB #blocks Id System
/dev/sda1 * 0+ 71680- 71681- 73400953+ 7 HPFS/NTFS/exFAT
/dev/sda2 71680+ 476938 405259- 414984520+ f W95 Ext'd (LBA)
/dev/sda3 0 - 0 0 0 Empty
/dev/sda4 0 - 0 0 0 Empty
/dev/sda5 71680+ 171686- 100007- 102406311 7 HPFS/NTFS/exFAT
/dev/sda6 171686+ 271693- 100007- 102406311 83 Linux
/dev/sda7 271694 273645 1952 1998848 82 Linux swap / Solaris
/dev/sda8 273647 476938 203292 208171008 83 Linux
Disk /dev/sdb: 1020 cylinders, 125 heads, 62 sectors/track
Warning: The partition table looks like it was made
for C/H/S=*/54/9 (instead of 1020/125/62).
For this listing I'll assume that geometry.
Units = mebibytes of 1048576 bytes, blocks of 1024 bytes, counting from 0
Device Boot Start End MiB #blocks Id System
/dev/sdb1 * 1 3860 3860 3952640 b W95 FAT32
start: (c,h,s) expected (4,11,6) found (0,32,33)
end: (c,h,s) expected (1023,53,9) found (492,53,9)
/dev/sdb2 0 - 0 0 0 Empty
/dev/sdb3 0 - 0 0 0 Empty
/dev/sdb4 0 - 0 0 0 Emptycfdisk
Là câu lệnh của phân vùng mở rộng trong linux, nó có giao diện dành cho người dùng tương tác dựa trên kernel của linux. Nó có các tính năng cao hơn sfdisk ở chỗ nó có thể chỉnh sửa hoặc tạo ra các partition.
Dưới đây là một ví dụ về cách sử dụng cfdisk để liệt kê các phân vùng.
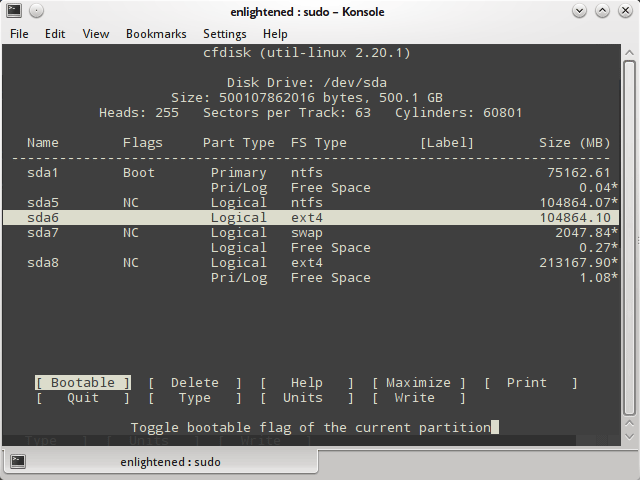
Nó có thể làm việc với một phân vùng tại một thời điểm cụ thể, bạn có thể xem chi tiết của một ổ đĩa
$ sudo cfdisk /dev/sdb
parted
đây là một câu lệnh để vượt ra giới hạn, có thể điều chỉnh thêm các partiton nếu cần thiết. Nó có thể liệt kê chi tiết các partion, dưới đây là ví dụ cụ thể về câu lệnh parted
$ sudo parted -l Model: ATA ST3500418AS (scsi) Disk /dev/sda: 500GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 32.3kB 75.2GB 75.2GB primary ntfs boot 2 75.2GB 500GB 425GB extended lba 5 75.2GB 180GB 105GB logical ntfs 6 180GB 285GB 105GB logical ext4 7 285GB 287GB 2047MB logical linux-swap(v1) 8 287GB 500GB 213GB logical ext4 Model: Sony Storage Media (scsi) Disk /dev/sdb: 4049MB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 4049MB 4048MB primary fat32 boot
df
đây là câu lệnh thường được dùng nhất trên hệ thống để kiểm tra dung lượng hdd, nó không hiển thị chi tiết các phân vùng nhưng nó có thể hiện thị chi tiết các thư mục được liên kết, nó có nhiều option các bạn có thể tự nghiên cứu nhé
$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda6 97G 43G 49G 48% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 3.9G 8.0K 3.9G 1% /dev tmpfs 799M 1.7M 797M 1% /run none 5.0M 0 5.0M 0% /run/lock none 3.9G 12M 3.9G 1% /run/shm none 100M 20K 100M 1% /run/user /dev/sda8 196G 154G 33G 83% /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1 /dev/sda5 98G 37G 62G 38% /media/4668484A68483B47
ở ví dụ trên, các thiết bị được bắt đầu bằng /dev mới là các thiết bị thực tế nên chúng ta cần lọc ra để xem cho dễ hơn
$ df -h | grep ^/dev /dev/sda6 97G 43G 49G 48% / /dev/sda8 196G 154G 33G 83% /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1 /dev/sda5 98G 37G 62G 38% /media/4668484A68483B47
để xem chi tiết các phân vùng thật và kiểu của phần vùng ta dùng câu lệnh như sau:
$ df -h --output=source,fstype,size,used,avail,pcent,target -x tmpfs -x devtmpfs Filesystem Type Size Used Avail Use% Mounted on /dev/sda6 ext4 97G 43G 49G 48% / /dev/sda8 ext4 196G 154G 33G 83% /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1 /dev/sda5 fuseblk 98G 37G 62G 38% /media/4668484A68483B47
chú ý: nó chỉ hiện thị các phân vùng được liên kết chứ không hẳn là tất cả đều đã được hiển thị trong câu lệnh df này nhé.
pydf
đây là một phiên bản cải tiến từ fd, nó được viết từ python, nó có nhiều ưu điểm hơn df ở chỗ nó có thể hiển thị tất cả các partition và dễ đọc, nhưng nó chỉ hiển thị các tập tin được liên kết thôi.
$ pydf Filesystem Size Used Avail Use% Mounted on /dev/sda6 96G 43G 48G 44.7 [####.....] / /dev/sda8 195G 153G 32G 78.4 [#######..] /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1 /dev/sda5 98G 36G 61G 37.1 [###......] /media/4668484A68483B47
lsblk
nó liệt kê ra các block bao gồm các partition và ổ đĩa quang, nó thể hiện dung lượng tổng kích thước của các partition và block và các phân vùng được liên kết nếu có. Nó không trả về dung lượng còn trống và dung lượng đã sử dụng
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 70G 0 part ├─sda2 8:2 0 1K 0 part ├─sda5 8:5 0 97.7G 0 part /media/4668484A68483B47 ├─sda6 8:6 0 97.7G 0 part / ├─sda7 8:7 0 1.9G 0 part [SWAP] └─sda8 8:8 0 198.5G 0 part /media/13f35f59-f023-4d98-b06f-9dfaebefd6c1 sdb 8:16 1 3.8G 0 disk └─sdb1 8:17 1 3.8G 0 part sr0 11:0 1 1024M 0 rom
Nếu câu lệnh trả về mà không có bất kỳ MOUNTPOINT nào thì nghĩa là không có bất kỳ file hệ thống nào được mout, đối với cd/dvd nghĩa là không có bất kỳ ổ đĩa nào tồn tại trong hệ thống.
Câu lệnh nó hiển thị về thông tin của mỗi thiết bị cũng như tên, đời của thiết bị.
blkid
câu lệnh trên trả về thông tin từng block của partition ( các partiton và các không gian lưu trữ media ) các thuộc tính giống như là uuid và loại file. Nó không trả về dung lượng của các partition
$ sudo blkid /dev/sda1: UUID="5E38BE8B38BE6227" TYPE="ntfs" /dev/sda5: UUID="4668484A68483B47" TYPE="ntfs" /dev/sda6: UUID="6fa5a72a-ba26-4588-a103-74bb6b33a763" TYPE="ext4" /dev/sda7: UUID="94443023-34a1-4428-8f65-2fb02e571dae" TYPE="swap" /dev/sda8: UUID="13f35f59-f023-4d98-b06f-9dfaebefd6c1" TYPE="ext4" /dev/sdb1: UUID="08D1-8024" TYPE="vfat"
hwinfo
đây là câu lệnh trả về các thông tin chính của phần cứng, nó được dùng để trả về thông tin của các ổ đĩa và danh sách các partition, tuy nhiên nó không đưa ra thông tin chi tiết về từng partiton như các câu lệnh ở trên.
$ hwinfo --block --short disk: /dev/sda ST3500418AS /dev/sdb Sony Storage Media partition: /dev/sda1 Partition /dev/sda2 Partition /dev/sda5 Partition /dev/sda6 Partition /dev/sda7 Partition /dev/sda8 Partition /dev/sdb1 Partition cdrom: /dev/sr0 SONY DVD RW DRU-190A
Tóm Lược:
Tất cả các câu lệnh trên trả về thông tin tóm tắt về các phần cứng, về các phân vùng khác nhau, hệ thống tập tin, dung lượng tổng. pydf và df nó giới hạn hiển thị, chỉ hiển thị các file hệ thống được gắn kết ( mount ).
fdisk và sfdisk thì cho chúng ta rất nhiều thông tin. cfdisk thì chỉ hiện thị một phân vùng tại một thời điểm nhất định.